



As generative AI systems evolve, so does the challenge of training them effectively. A common frustration among model developers is the diminishing return from human data: more data is fed into the model, but performance plateaus. This phenomenon is often misunderstood as a sign that the model has reached its capacity. In reality, it’s usually a sign of low-quality human data.
The assumption that “more is better” with data can backfire when the data itself lacks depth and complexity. AI systems don’t just need more data—they need better data. Low-quality human datasets tend to be overly simplistic, repetitive, or narrowly targeted toward benchmark tests. As a result, even with increasing volumes of data, critical performance gaps remain.
Invisible’s data strategy team worked with a client building a foundation model using multiple human data vendors. Despite their investment, they reported that their model struggled to follow instructions. But after evaluating the model, we found that it wasn’t actually bad at following instructions—it was bad at sorting and executing multi-step or conceptual tasks.
The issue wasn't quantity, but task complexity. Instead of using basic prompts like “classify this text” or “extract this phrase,” we trained human annotators to simulate real-world user behavior—like combining sorting with analysis or reasoning. When we zeroed in on sorting as a key failure point, we saw a 22% performance improvement across all instruction-following tasks.
Why? Because many user prompts combined sorting with other instructions. Improving this one capability lifted the model's overall instruction-following accuracy.
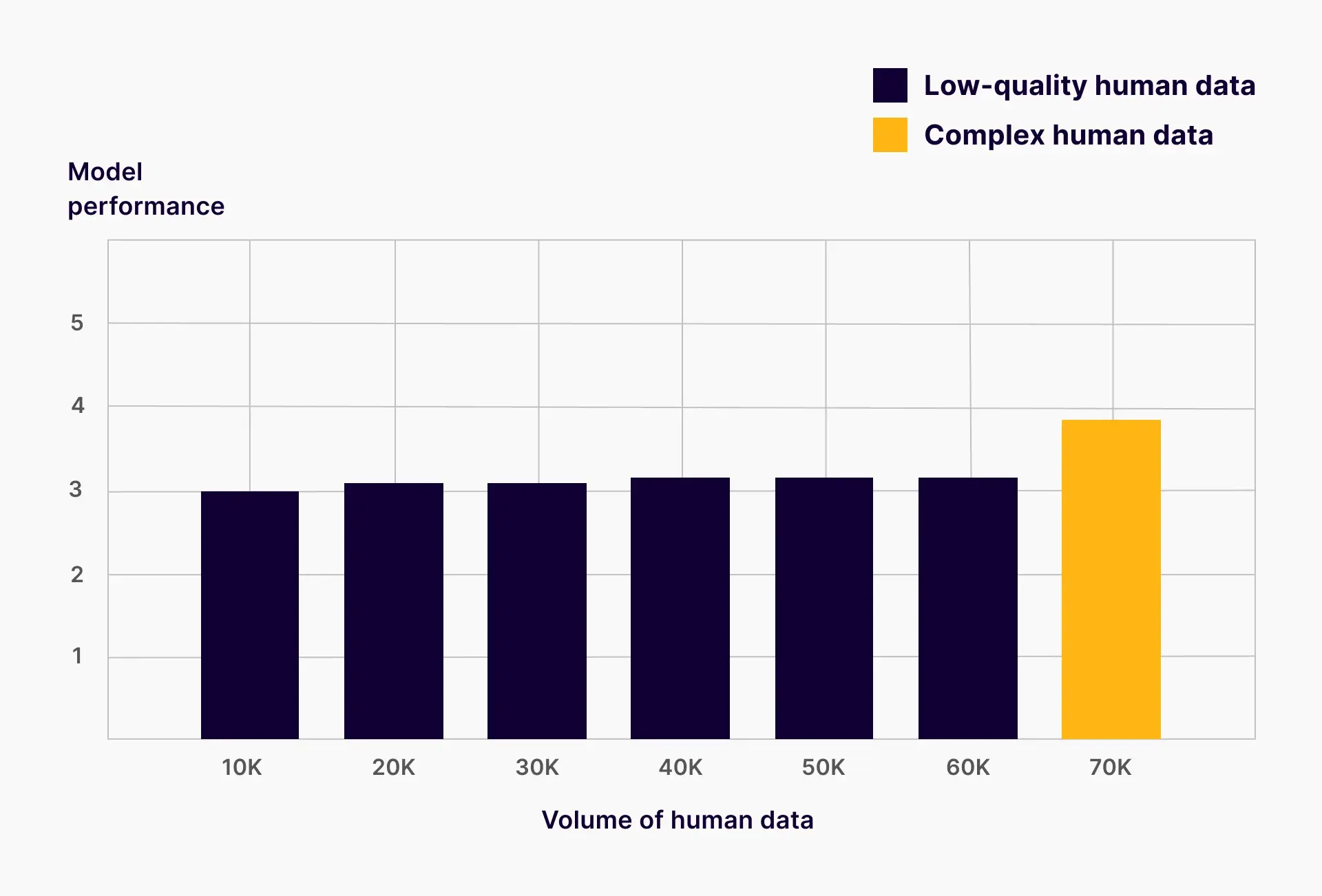
Another common indicator of low quality human data that we see often is overfitting to industry benchmarks. Labs are under pressure to outperform on standardized tests like MMLU or IFEVAL. But training models just to perform well on benchmarks is like teaching to the test—it produces high scores, but poor real-world adaptability.
When models are only exposed to narrow, hyper-specific training data, their creative and generative capabilities are stunted. These models perform impressively within the lines drawn by benchmarks but fall apart when asked to generate or reason outside those lines. This is especially dangerous in generative AI, where adaptability and creative reasoning are core requirements.
To successfully train a generative AI model, we have to let the model generate—not regurgitate its training data.
The path forward starts with custom model evaluations tailored to real-world use cases. These evaluations identify where your model truly underperforms—not just on paper, but in practice.
Next comes redefining what we mean by complexity. It’s not just about adding more steps to a task. Complexity can be:
Both are valid, but only the latter requires the conceptual reasoning capabilities to handle an open-ended, subjective prompt. Models trained exclusively on procedural prompts may ace benchmarks but fail at more human-centric tasks.
If your model seems stuck, it’s not because it has learned all it can from human data—it’s likely because the data lacks the richness required to push it further. High-performing models are not built on volume alone, but on diverse, creative, and contextually complex human input.
Want to break through the plateau? Start with a custom model evaluation. It’s the best way to understand your model’s real limits—and the quality of the data it’s learning from.


